|
|||||||||
| PREV NEXT | FRAMES NO FRAMES | ||||||||
See:
Description
| Packages | |
|---|---|
| com.reverseXSL |
The reverseXSL software provides two interfaces:
The command line interface is described in this one package.
The API, comprising the Transformer,
TransformerFactory, and lower-level
Parser objects; cfr these other
packages.
|
| com.reverseXSL.exception | |
| com.reverseXSL.message | |
| com.reverseXSL.parser | |
| com.reverseXSL.transform | |
| com.reverseXSL.types | |
| com.reverseXSL.util | |
The com.reverseXSL package provides any-to-any message transformation capabilities for text-based data, using XML as pivotal format.
This package contains an original text-based-document parser that transforms character-based data to data element trees rendered here as XML. It complements the XML-to-anything transformation capabilities of XSLT with anything-to-XML transformation functions. XSLT is an component of the java API for XML processing (JAXP - javax.xml.transform) which is included in all recent Java language runtime libraries and not in this software. The software requires a Java runtime environment (JRE) version 1.4.2 or later, and relies on JAXP for proper operation.
The Parser can handle flat files containing plain text as well as control characters, with mixed fields of variable and fixed size formats, composite structures nested in each other, repeating groups of elements at any level, explicit and implicit field separators, optional structures, validity conditions, plus simple and complex interdependencies (element-to-element, element-to-value, value-to-element, value-to-value). The parser operates internally on UNICODE characters, and accepts all input/output encodings in the java Charsets (iso-8859-x, UTF-8, UTF-16 BE/LE/BOM, JIS, EBCDIC, ASCII, legacy code pages, etc.).
The Parser component alone excels at converting complex text-based structures to XML; it can change nesting levels (flatten or enrich), as well as hide data values or supply additional information based on the evaluation of conditions, but it cannot re-order data elements, neither combine values from different places in the source message. These last functions are actually delegated to an optional XSLT transformation step next to the Parsing in proper.
By analogy to XSLT which is built over XPath expressions, the reverseXSL Parser is based on regular expressions (package java.util.regex) which it uses in turn and recursively to identify (i), cut (c), extract (e), and validate (v) information. By analogy to XSLT which interprets XSL templates to transform tree-structures (XML) to any character-based document, the reverseXSL parser interprets DEF files (message DEFinitions) to transform character-based documents into tree structures (rendered as XML).
The tool bundles three main data processing steps:
In a typical application context, or enterprise gateway, the same processing chain applies to both flow directions, for instance from EDI to XML and from XML to EDI, by just a proper setting of meta-data, and notably the combining of Parsing and XSL transformation stages.
The software is entirely driven by meta-data. No code is generated. The transformation-profile matching step makes use of a mapping-selection-table. The Parsing step makes use of message DEFinition files, and the XSL Transformation step is driven by XSL templates. All meta-data is loaded from plain text file representations to be found within regular directories and/or on the classpath (through the java classloader). The mechanisms are identical to those used for java .class files.
The package takes the form of a java archive (.jar) file that contains the software as well as all meta-data resources required to handle a given set of message formats. New or extended message sets can be supplied as releases of the main jar file, or as additional and separate jar files. External ad-hoc meta data files are also often used in testing.
The package contains two main classes: TransformerFactory and Transformer, similar to the javax.xml.transform package. The Transformer factory encapsulates all details regarding the source of meta-data (precisely, whether to use embedded data, data from an external jar, or from specific files), as well as message transformation parameters linked to an operational context (thresholds, charsets, message de-pollution). The TransformerFactory is then used to instantiate one or a few Tranformers that will actually do the job. Transformers can be spawned in different threads. They will then all share the same meta-data source defined at factory time. When instantiated from the same factory, Transformers can still be differentiated by their base counter for generating message identifiers (an automatic XML root-element attribute).
It is best illustrated through the following sample code. It takes only 3 effective lines of code!
try { //you must catch exceptions, as any failure to transform the input message // results in an exception. No exception means OK. //1. Get a default transformer factory with: TransformerFactory tf = TransformerFactory.newInstance(); //That one will use all meta-data resources embedded in the main jar file. //Alternative factory methods support variant meta-data sources //2. Instantiate a transformer: Transformer t = tf.newTransformer(); //Use an Input Stream and an Output Stream of whatever type: // Byte Array, File or else ByteArrayInputStream bais = new ByteArrayInputStream(myInputMessage); ByteArrayOutputStream baos = new ByteArrayOutputStream(); //3. Execute the transformation int parserWarnings = t.transform(is, os); //DONE! just take the transformed message from the output stream. //The parser, if invoked in the transformation, is able to tolerate //minor message syntax deviations (this is entirely parametrizable) //up to given thresholds (set via the factory API). The integer that //is returned tells how many syntax violations were actually detected //with a count still below thresholds: by default, 10 warnings are //accepted, and zero major error. //You may be interested in: StringBuffer sb = t.getLog(); ListIterator li = t.getParserExceptionListIterator(); } catch (Exception e) { //put your exception handling code here. }
The sketch below outlines the internal architecture of the tool, and how its components are used for INbound and OUTbound message handling. We assume here an OUTside world talking in some legacy text-based format, and an INside world in XML. It can well be the opposite: the adaptation of an internal legacy application that features data import/export in proprietary text-based layouts, to an external XML world.
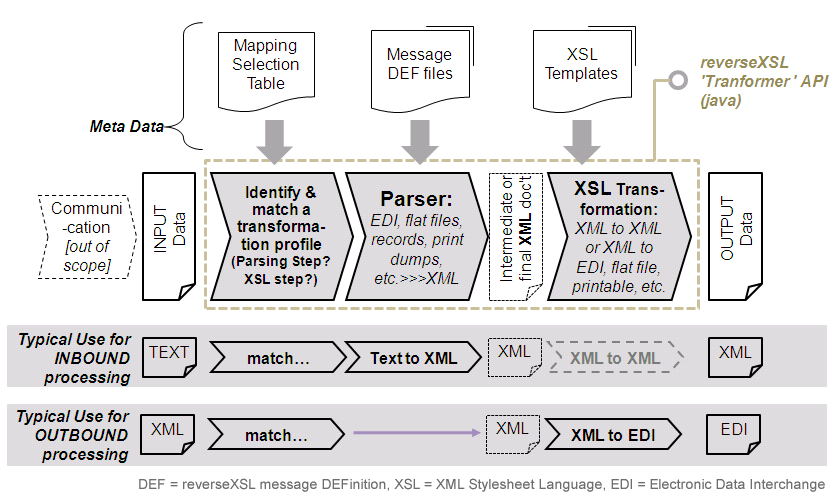
Meta-data can be divided in three categories:
javax.xml.transform package.
XSL Transformations (XSLT) is a W3C specification documented elsewhere in numerous web sites and books.
Such meta data is found under sub-dir resources within the jar archive file itself:
[jar file.jar]--+-META-INF/---MANIFEST.MF | +-resources/--+--XSLT/--*XSL Templates for XML-to-XML and XML-to-EDIorTEXT (meta-data) | | | +--DEF/---*Parser DEF files for EDIorTEXT-to-XML (meta-data) | | | +-TABLES/--Mapping Selection Table (meta-data) | +-com/reverseXSL/... : reverseXSL java classes, including the Transformer | +-reference/... : reference message schemas and samples (to extract from the jar) | +-samples/---Example input messages (to extract from the jar)
The jar file also contains reference data: XML Schemas and sample files. This reference directory and everything below is only informative. They are not needed for correct software operation but conveniently shipped with the software itself.
|
|||||||||
| PREV NEXT | FRAMES NO FRAMES | ||||||||