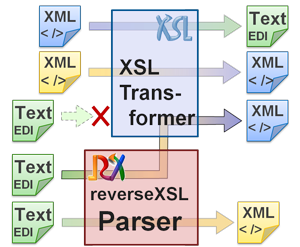
The reverseXSL Transformer Features
At a glance
- Syntaxical parser capable of transforming any structured character file into an XML document
- Domain-specific meta-data language describes the expected syntax and drives identifications, validations, extractions and cuts based on Regular expressions
- Java source code; use the Java API or a command line executable in a shell or command script
- build a single .jar file that packs the code with meta-data resources, or keep meta-data separate and integrate the jar as a micro-service
- Perfect complement to XSLT (XML to anything) for mapping anything to XML
- OPEN SOURCE, Apache 2.0 license
Text to XML: converting loosely-structured text data
How much Un-structure can you afford to handle?
Whereas most parsers require well defined delimiters, tags, or fixed size fields to grasp data fields and carry on transformations, the parser that we are about to present is capable of extracting data from look-alike stuff. Its mapping power is directly related to that of regular expressions which are state-of-the-art in pattern matching. Data resisting pattern matching by being even less structured would imply concepts like ontologies and semantic nets which are not in scope here.
There is a significant gap between a regular expression software library providing just the raw capability to match a pattern, as sophisticated as it can be, and the final production of an XML document. That is indeed the added value of the reverseXSL software: regular expressions are organized to conduct four tasks (identify, cut, extract, and validate) in turn, and recursively, till reaching the atoms of data which must be output into your XML document.
EDI to XML: converting a legacy EDI Message to XML
Whether IATA Cargo-IMP, AHM, SSIM, SWIFT, EDIFACT, X12, EDIFICE, EANCOM, TRADACOMS, GENCOD, IEF, SPEC-2000... just name them and you can transform these Electronic Data Interchange standards with this tool... both ways: EDI to XML (with the Parser and optionally XSLT) and XML to EDI (with XSLT).