How much Un-structure can you afford to handle?
Whereas most parsers require well defined delimiters, tags, or fixed size fields to grasp data fields and carry on transformations, the parser that we are about to present is capable of extracting data from look-alike stuff. Its mapping power is directly related to that of regular expressions which are state-of-the-art in pattern matching. Data resisting pattern matching by being even less structured would imply concepts like ontologies and semantic nets which are not in scope here.
There is a significant gap between a regular expression software library providing just the raw capability to match a pattern, as sophisticated as it can be, and the final production of an XML document. That is indeed the added value of the reverseXSL software: regular expressions are organized to conduct four tasks (identify, cut, extract, and validate) in turn, and recursively, till reaching the atoms of data which must be output into your XML document.
Table of Contents
- A Product Unlike Others
- The Tutorial Example
- Drafting the DEF file
- Introducing line cuts (segmentation)
- Sub-grouping
- Handling UNtagged Repetitions
- Matching by Exclusion
- Handling UNordered data
- Advanced Concepts: Conditions and Marks
- The Final Touch
A Product Unlike Others: compact, simple to learn, very simple to deploy, and extremely flexible
ReverseXSL is a software tool digesting meta-data definitions of arbitrary formats, and turning the corresponding message instances to XML. The meta language used in reverseXSL DEF files can describe all kinds of formats, in ASCII, ISO, JIS, or Unicode brands, with plenty of non-printable characters, highly structured like EDI brands, or much unstructured like printed data, and all intermediate character-based formats mixing fixed, variable, and vicious(!) syntax exported from IT applications
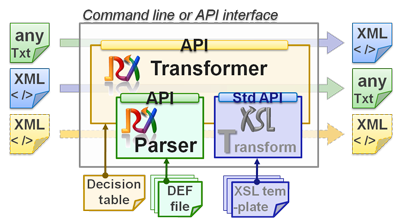 ReverseXSL software is NOT a workstation package with graphical editors for numerous embedded tools and (often limitative) families of formats. ReverseXSL software is neither a library of parsing functions that you'll need to call in a proper sequence in order to advance in the source file and capture data (e.g. like the SAX API). Instead, reverseXSL software is contained in a single java archive, which you invoke from the command line, an Excel macro, or MS-Windows script, or a shell script, or else the java API directly. The reverseXSL software takes your raw text file as input, uses a message DEFinition file describing the transformation, and produces an XML output.
ReverseXSL software is NOT a workstation package with graphical editors for numerous embedded tools and (often limitative) families of formats. ReverseXSL software is neither a library of parsing functions that you'll need to call in a proper sequence in order to advance in the source file and capture data (e.g. like the SAX API). Instead, reverseXSL software is contained in a single java archive, which you invoke from the command line, an Excel macro, or MS-Windows script, or a shell script, or else the java API directly. The reverseXSL software takes your raw text file as input, uses a message DEFinition file describing the transformation, and produces an XML output.
The reverseXSL software plus a DEF file describing the input syntax is all what is needed!
You can actually put the DEF file in the software archive itself, so you would just need to pass your input data file as argument to a java program contained in a single jar (inclusive of meta-data). Moreover, The reverseXSL Transformer automates the combined use of XSLT and the reverseXSL Parser, with the help of a mapping decision table. The Transformer identifies arbitrary input messages, looks up the decision table for relevant Transformation steps, and executes these. Therefore, the Transformer maps XML to XML, XML to flat / text or EDI, EDI to XML, text to XML, text to flat, EDI to flat, and so forth. It can also act as a pass-through for selected messages, thus generalizing the means to import and export data for target applications.
The magic is the ease of learning the DEF meta language; it contains only five constructs: segments, groups, data elements, marks and conditions. These five constructs organise the use of regular expressions and simple built-in functions to drive parsing and to produce the target XML document.
The software distribution jar (reverseXSL.jar) contains various samples, but the one at stake here is available separately for download from the tutorial samples container.

The text file at stake is illustrated in the enclosed figure.
The example is a listing of contact names and addresses each separated from the next by a single dot character.
Each address block contains a variable number of lines with no tags except for some trailing telephone, fax and mobile numbers. The only bits of structure that we can use are as follows
· The first line always contains the name, optionally followed by a comma and a job position;
· one or two indented lines may optionally follow with a company name and then office location;
· then follows a variable number of unstructured address lines;
· followed by a postcode, tab, and city name;
· most of the time (but not always!) followed by a line with the country name;
· and terminating with optional email address (no tag), telephone, fax and mobile numbers, each on a separate line but in any order.
The objective is to properly segregate the different pieces of information and produce the XML document illustrated below. To make the job a little more challenging, the parser recovers missing country names from the look of the post code where feasible.
It took me 1,5 hours to produce the final DEF file, inclusive of testing and tuning of the patterns for best results.
<?xml version="1.0" encoding="UTF-8"?>
<AddressListing xmlns="http://www.reverseXSL.com/FreeParser">
<Record>
<Name>Kenjira Fuyamara Watanabe</Name>
<Office>
<Company>GOBAN Corp ltd.</Company>
<Location>4th fl Serm-mit tower</Location>
</Office>
<Address>
<Line>279B, Sukhumvit 21 road</Line>
<Line>Klongtoey Nua, Wattana</Line>
</Address>
<PostCode>10110</PostCode>
<City>Bangkok</City>
<Country>Thailand</Country>
<Contact>
<InternetMail>This email address is being protected from spambots. You need JavaScript enabled to view it. </InternetMail>
</Contact>
</Record>
<Record>
<Name>John Mapitnaw</Name>
<Position>General Mgr</Position>
<Office>
<Company>MYRIADICS Inc.</Company>
</Office>
<Address>
<Line>Blue Business Centre</Line>
<Line>366, Crossburn Avenue</Line>
</Address>
<PostCode>NY 10080</PostCode>
<City>New York</City>
<Country>United States</Country>
<Contact>
<Telephone>+1(100)23456789</Telephone>
<MobilePhone>+1(678)12332100</MobilePhone>
</Contact>
</Record>
<Record>
<Name>Bernard Zerault</Name>
<Address>
<Line>55B, rue Fleurie</Line>
</Address>
<PostCode>F95600</PostCode>
<City>Webville</City>
<Country>France</Country>
<Contact>
<InternetMail>This email address is being protected from spambots. You need JavaScript enabled to view it. </InternetMail>
<Fax>+33(2)87654321</Fax>
</Contact>
</Record>
</AddressListing>
You can run the tutorial example by executing the DOS batch file supplied in the downloadable material. This is simplistic. The best method is indeed to integrate the reverseXSL software inside your run-time application by calling the java API as explained in the javadoc.
The DEF file entirely defines the parsing of the text input and its transformation to XML. The file simply contains nested segments (SEG), groups (GRP) and data (D) definitions.
You may like to open a separate window on the entire DEF file. Next to a full page of comments, a DEF file is always comparable in size to an XML schema for the target document.
The first important piece of meta data in the DEF file is the MSG definition (nearby line 51), which is actually a SEGment matching the entire file:
MSG "" AddressListing M 1 1 ACC 1 R W "Address Listing File" CUT-ON-NL
- MSG is the keyword. MSG is the topmost SEGment.
- "" is actually a regex (regular expression) used to identify this segment: the regex is obviously empty and can therefore be found in any string. In other words, the Parser implicitly assumes that this is the right file/Message brand.
- AddressListing defines the XML root element name.
- M 1 1 ACC 1 is fixed in case of a MSG. It tells that this segment is Mandatory, formally occurs min=1 and max=1, and the Parser can actually ACCept 1.
- R W instructs to Record a Warning exception if anything goes wrong at this stage.
- then follows a "description..." to be reported in error messages.
- then follows the segment cutting function, here CUT-ON-NL, a built-in function telling to simply CUT the segment/entire-file ON New Line boundaries (CRLF or LF or CR alone
The outcome of all this is that the Parser assumes the entire file/segment as being an Address Listing and cuts it in individual lines. A Warning exception would be recorded on the unlikely event that the cut fails.
The result from the MSG cut is a collection of lines which is in turn presented for potential matches to the next definition object.
This object is a group definition, formalizing the fact that our text file is the collection of address records terminated by a single dot line; as follows:
MSG ... as defined above ...
|GRP "" Record M 1 9999 ACC 9999 R W "Complete Address Record"
||D "(..+)" _To_be_Parsed_ M 1 99 ACC 99 R W "TO DO" ASMATCHED
||D "(\\.)" EndOfRec M 1 1 ACC 1 R W "Single-dot rec.-sep." ASMATCHED
END
The above DEFinition is indeed a first draft as you may develop it.
- The first | of the GRP line make it a sub-element of MSG; and the two || in front of D lines make them sub-elements of GRP.
- GRP and D are indeed the keywords for Groups and Data elements. END marks the end of the entire message DEFinition.
- Like our MSG, the GRP definition features an empty regex "", meaning that whatever piece of the input message we have to tentatively match at this point (actually the very first line resulting from the MSG cut), we assume that an instance of this group starts now, which will later generate the corresponding Record tag in the output XML document.
Just below, the regex of the first Data definition "(..+)" will match .any-char followed by .any-char +repeated at least once; in other words, any line with at least 2 characters. On the other hand the second Data element regex "(\\.)" matches only with a \\.true-dot char, alone.- M 1 9999 ACC 9999 means that the group is Mandatory, formally from min 1 to max 9999 occurences, and the parser is entitled to ACCept the formal maximum of 9999 occurences. A similar reading of the M 1 99 ACC 99 on the first Data line indicates that it is a Mandatory member of the group that can repeat 99 times, whereas the next single-dot Data is Mandatory and can't repeat (min=1 max=1 ACCept=1).
The cardinality notation allows differentiating formally specified limits from those practically accepted for parsing purposes. For instance, a setting like O 1 2 ACC 5 indicates that the element is Optional (parsing will not fail if not found) and the parser can ACCept 5 repetitions (parsing may tolerate such repetitions). However, any deviation from min 1 and max 2 occurrences will be reported according to the following two letters, explained just next.
- All defintions are marked with R W asking to Record Warnings in case of errors.
Indeed, the Parser can be instructed to either Record exceptions (hence trying to keep on with parsing) or Throw them (hence interrupting the execution). And errors can be qualified as Fatal or Warnings. The Parser is actually tolerant towards a parametrizable number of recorded Warnings. One can also make it tolerant to more than one Fatal error, which is weird (what is the meaning of Fatal?) but helpful in the course of development.
- Each DEF line has a "description..."
- .
- The last keyword in Data definitions is always the extracted data value validation function. Here ASMATCHED simply means that no further validation is carried on than already made while matching the regular expressions "(..+)" and "(\\.)" respectively.
The outcome of all this is that an instance of the group is created,then each line with at least 2 chars is matched as a Data _To_be_Parsed_, repeatedly 'eating' cut lines till one is encountered with a single dot. At this point the Parser fails to match one more occurence of _To_be_Parsed_ and tries the next Data definition, i.e. EndOfRec, actually matching the single dot, but not allowed to repeat. Having exhausted the two group sub-elements, the parser closes the current group instance and tries to match a new occurence of the same group, because the group itself can repeat. The parser will sucessfully repeat the matching of group children elements till it reaches the last cut line. Having exhausted all lines cut from the MSG, no more group instance can be matched and the message itself is closed.
It is important to understand that a group does not eat any piece of the input message. The input context is left unchanged. A group is a pure logical beast, often used to repeat—like here—the parsing of a sequence of segments, data elements and other (sub)groups, else used to mark element hierarchies in the generated XML.
Applying the above draft DEFinition to the input file, we get the raw XML:
<?xml version="1.0" encoding="UTF-8"?>
<AddressListing xmlns="http://www.reverseXSL.com/FreeParser">
<Record>
<_To_be_Parsed_>Kenjira Fuyamara Watanabe</_To_be_Parsed_>
<_To_be_Parsed_> GOBAN Corp ltd.</_To_be_Parsed_>
<_To_be_Parsed_> 4th fl Serm-mit tower</_To_be_Parsed_>
<_To_be_Parsed_>279B, Sukhumvit 21 road</_To_be_Parsed_>
<_To_be_Parsed_>Klongtoey Nua, Wattana</_To_be_Parsed_>
<_To_be_Parsed_>10110 Bangkok</_To_be_Parsed_>
<_To_be_Parsed_>Thailand</_To_be_Parsed_>
<_To_be_Parsed_>This email address is being protected from spambots. You need JavaScript enabled to view it. </_To_be_Parsed_>
<EndOfRec>.</EndOfRec>
</Record>
<Record>
<_To_be_Parsed_>John Mapitnaw, General Mgr</_To_be_Parsed_>
<_To_be_Parsed_> MYRIADICS Inc.</_To_be_Parsed_>
<_To_be_Parsed_>Blue Business Centre</_To_be_Parsed_>
<_To_be_Parsed_>366, Crossburn Avenue</_To_be_Parsed_>
<_To_be_Parsed_>NY 10080 New York</_To_be_Parsed_>
<_To_be_Parsed_>Tel:+1(100)23456789</_To_be_Parsed_>
<_To_be_Parsed_>Mob:+1(678)12332100</_To_be_Parsed_>
<EndOfRec>.</EndOfRec>
</Record>
<Record>
<_To_be_Parsed_>Bernard Zerault</_To_be_Parsed_>
<_To_be_Parsed_>55B, rue Fleurie</_To_be_Parsed_>
<_To_be_Parsed_>F95600 Webville</_To_be_Parsed_>
<_To_be_Parsed_>France</_To_be_Parsed_>
<_To_be_Parsed_>This email address is being protected from spambots. You need JavaScript enabled to view it. </_To_be_Parsed_>
<_To_be_Parsed_>Fax:+33(2)87654321</_To_be_Parsed_>
<EndOfRec>.</EndOfRec>
</Record>
</AddressListing>
We can easily get rid of the useless EndOfRec data elements in the generated XML if we simply rename them by the reserved tag SKIP in the DEFinition (as you may observe in the last lines of the complete sample DEF file).
||D "(\\.)" SKIP M 1 1 ACC 1 R W "Single-dot rec.-sep." ASMATCHED
So far we have cut the input file along line boundaries, and matched every line in collections reflecting the first-level structure of the file, that of contact Record’s.
Introducing line cuts (segmentation)
The first line of each address record is implicitly always the name of the person. Therefore no pattern will be needed to identify it.
Precisely, the "" pattern always returns a positive match, and is used here.
The name itself can be optionally followed by a , and the professional position or role of the person. We shall cut, or say, SEGment it in its two constituents, which we respectively match against two child Data elements, the second being optional.
The cardinality definition O 0 1 ACC 1 means Optional, formally min 0 max 1, parser ACCepts 1
The relevant DEFinition becomes:
MSG "" AddressListing M 1 1 ACC 1 R W "Address Listing File" CUT-ON-NL
|GRP "" Record M 1 9999 ACC 9999 R W "Complete Address Record"
||SEG "" Person M 1 1 ACC 1 R W "1st l.: Name and Pos." CUT-ON-(,)
|||D "(.*)" Name M 1 1 ACC 1 T F "Name" ASMATCHED
|||D "^ *(.*)" Position O 0 1 ACC 1 R W "Position ..." ASMATCHED
||D "(..+)" _To_be_Parsed_ M 1 99 ACC 99 R W "Yet to..." ASMATCHED
||D "(\\.)" SKIP M 1 1 ACC 1 R W "Single-dot rec-sep." ASMATCHED
END
The SEGment CUT-ON-(,) function decomposes a line like:
John Mapitnaw, General Mgr
strictly into:
John Mapitnaw , General Mgr
leaving the second field with a leading space character.
The data validation and extraction pattern for the second data element is adjusted to extract only the trimmed value as follows: "^ *(.*)" reading as ^start of string followed by a space-char *repeated zero-or-more, followed by the ( )capture of ( .any-char *repeated ).
When the reverseXSL parser is asked to apply the above DEFinition against our input sample, we get an XML document like:
<AddressListing xmlns="http://www.reverseXSL.com/FreeParser">
... some records not illustrated here ...
<Record>
<Person>
<Name>John Mapitnaw</Name>
<Position>General Mgr</Position>
</Person>
<_To_be_Parsed_> MYRIADICS Inc.</_To_be_Parsed_>
<_To_be_Parsed_>Blue Business Centre</_To_be_Parsed_>
<_To_be_Parsed_>366, Crossburn Avenue</_To_be_Parsed_>
<_To_be_Parsed_>NY 10080 New York</_To_be_Parsed_>
<_To_be_Parsed_>Tel:+1(100)23456789</_To_be_Parsed_>
<_To_be_Parsed_>Mob:+1(678)12332100</_To_be_Parsed_>
</Record>
... more records not illustrated here ...
</AddressListing>
The Person tag is not much useful; if we prefer a simpler structure where Name and Position are direct children of Record, we simply rename the SEGment tag Person into this other reserved tag NOTAG.
This is easy: A segment definition (SEG) automatically becomes the parent element of the pieces resulting from its CUT / segmentation; a group (GRP) is automatically the parent of its member elements (data, sub-groups, or segments). Whenever you want to get rid of such parent level in the XML output, just name the segment or group with 'NOTAG'.
If we modify the SEGment definition as:
||SEG "" NOTAG M 1 1 ACC 1 R W "1st l.: Name and Pos." CUT-ON-(,)
we get the output:
<AddressListing xmlns="http://www.reverseXSL.com/FreeParser">
... some records not illustrated here ...
<Record>
<Name>John Mapitnaw</Name>
<Position>General Mgr</Position>
<_To_be_Parsed_> MYRIADICS Inc.</_To_be_Parsed_>
<_To_be_Parsed_>Blue Business Centre</_To_be_Parsed_>
<_To_be_Parsed_>366, Crossburn Avenue</_To_be_Parsed_>
<_To_be_Parsed_>NY 10080 New York</_To_be_Parsed_>
<_To_be_Parsed_>Tel:+1(100)23456789</_To_be_Parsed_>
<_To_be_Parsed_>Mob:+1(678)12332100</_To_be_Parsed_>
</Record>
... more records not illustrated here ...
</AddressListing>
Next in the address Record we get zero, one, or two indented lines like:
GOBAN Corp ltd. supplies a company name
4th fl Serm-mit tower supplies an office or desk location
There's nothing to cut further down at this point. The whole message is already CUT on new line boundaries, so we can directly match each above line with a sequence of Data DEFinitions like:
||D "^ (.*)" Company O 0 1 ACC 1 R W "Company name..." ASMATCHED
||D "^ (.*)" Location O 0 1 ACC 3 R W "Office Loc..." ASMATCHED
where the pattern "^ (.*)" plays a twofold role: (1) identify: ensuring that we match something starting with a ^leading space-char. (2) extract: the following ( )capture of ( .any-char *repeated ).
The cardinality of both is O 0 1 Optional min 0 max 1 (officially). The parser is instructed to ACCept only 1 Company element (more will cause office location data to be matched as a repeated Company name! yet report a deviation with the official max 1), and ACCept up to 3 Office location lines... so as to give extra chances for the parsing to continue in case of extra indented lines.
The entire Record DEFinition becomes:
|GRP "" Record M 1 9999 ACC 9999 R W "Complete Address Record"
||SEG "" NOTAG M 1 1 ACC 1 R W "1st l.: Name and Pos." CUT-ON-(,)
|||D "(.*)" Name M 1 1 ACC 1 T F "Name" ASMATCHED
|||D "^ *(.*)" Position O 0 1 ACC 1 R W "Position..." ASMATCHED
||D "^ (.*)" Company O 0 1 ACC 1 R W "Company name..." ASMATCHED
||D "^ (.*)" Location O 0 1 ACC 3 R W "Office Loc..." ASMATCHED
||D "(..+)" _To_be_Parsed_ M 1 99 ACC 99 R W "Yet to..." ASMATCHED
and yields for instance the XML fragment:
<Record>
<Name>Kenjira Fuyamara Watanabe</Name>
<Company>GOBAN Corp ltd.</Company>
<Location>4th fl Serm-mit tower</Location>
<_To_be_Parsed_>279B, Sukhumvit 21 road</_To_be_Parsed_>
<_To_be_Parsed_>Klongtoey Nua, Wattana</_To_be_Parsed_>
<_To_be_Parsed_>10110 Bangkok</_To_be_Parsed_>
<_To_be_Parsed_>Thailand</_To_be_Parsed_>
<_To_be_Parsed_>This email address is being protected from spambots. You need JavaScript enabled to view it. </_To_be_Parsed_>
</Record>
In the previous section, we changed Person into NOTAG to suppress a hierarchical level. Now, we would like to enhance the semantical structure in XML with an additional hierarchy: an Office element around both Company and Location, such as to get:
<Record>
<Name>Kenjira Fuyamara Watanabe</Name>
<Office>
<Company>GOBAN Corp ltd.</Company>
<Location>4th fl Serm-mit tower</Location>
</Office>
<_To_be_Parsed_>279B, Sukhumvit 21 road</_To_be_Parsed_>
... rest of record unchanged ...
thanks to the introduction of a new Office group in the DEFinition, as follows:
|GRP "" Record M 1 9999 ACC 9999 R W "Complete Address Record"
||SEG "" NOTAG M 1 1 ACC 1 R W "1st l.: Name and Pos." CUT-ON-(,)
|||D "(.*)" Name M 1 1 ACC 1 T F "Name" ASMATCHED
|||D "^ *(.*)" Position O 0 1 ACC 1 R W "Position..." ASMATCHED
||GRP "^ " Office O 0 1 ACC 1 R W "Office group..."
|||D "^ (.*)" Company M 1 1 ACC 1 R W "Company name..." ASMATCHED
|||D "^ (.*)" Location O 0 1 ACC 3 R W "Office Loc..." ASMATCHED
||D "(..+)" _To_be_Parsed_ M 1 99 ACC 99 R W "Yet to..." ASMATCHED
Where the depth of both Company and Office elements has been increased by one | to become children of the new group.
There are two other important changes: (1) the new Office group features an identification pattern "^ " matching strings ^starting with a space (whatever follows is left unspecified). (2) this group is Optional and non repeatable (cardinality O 0 1 ACC 1), whereas at the same time its first member element Company becomes Mandatory (M 1 1 ACC 1).
Next to the indented and optional Office and Location lines we get a series of plain address lines, without any tags or syntaxical hooks, terminated by the appearance of the PostCode_tab_City line. The tab character in it is actually the key that breaks the repetition of address lines! Address lines are simply lines with no tabs. They will match the pattern ([^\\t]*) meaning the ( )capture of ( character in the [ ]list of [ ^not-being a \\ttab ] *repeated ).
So we can eat all plain address lines with a DEFinition like:
||D "([^\\t]*)" AddressLine M 1 3 ACC 5 R W "Address line" ASMATCHED
M 1 3 ACC 5 means that the address line is Mandatory, at least 1, and up to 3 formally, but we let the parser ACCept up to 5. We may like to change it to O 1 3 ACC 5 so that the parser tolerates finding no address line at all, yet will Report a Warning about the missing min count of 1.
Strong of explanations in former sections, we can guess that the above DEFinition will yield a repetition of AddressLine elements directly under the Record tag. Not very nice... we would better have something line <Address> <Line> <Line> <Line> </Address> ... easily achieved with a Group DEFinition like:
||GRP "" Address M 1 1 ACC 1 R W "Address lines group"
|||D "([^\\t]*)" Line M 1 3 ACC 5 R W "Address line" ASMATCHED
Worth noting, the identification pattern of the group is "" which, by definition, matches everything. Why not using a pattern like "[^\\t]*" meaning not-a-tab-repeated? That can indeed be an improvement. But the group is Mandatory (at least one address line is required) so the same error will be detected while tentatively matching a data element member of this group, for which a not-a-tab-repeated pattern is used. Thus both are syntaxically equivalent—the way the error is reported will differ.
Assuming that we have segmented the PostCode_tab_City line on the middle tab (see the complete DEF file nearby lines 65 to 68), we fall just next on an optional country line, again with no tag, and no syntaxical hook for a positive identification. We shall again seek help from what comes next in order to identify it negatively, i.e. as not being anything that can possibly follow. The problem is a bit more tricky, because a collection of unordered lines shall be expected (Tel:, Mob:, Fax:, e@mail). The next certain element is the single-dot end-of-record marker, as illustrated in the example input address record below.
John Mapitnaw, General Mgr
MYRIADICS Inc.
366, Crossburn Avenue
NY 10080 New York Mandatory PostCode_tab_City line
United States Optional!
Tel:+1(100)23456789 optional |
Mob:+1(678)12332100 optional | in any orderThis email address is being protected from spambots. You need JavaScript enabled to view it. optional |
Fax:+1(100)23456001 optional |
.
Our identification strategy will be here to exclude the explicit tags in most of the possibly following lines, as well as exclude the very specific dot-alone marker, and the internet mail address @-pattern. This is an opportunity to illustrate the use of a zero-width-negative-lookahead regular expression (the name sounds more weird than the expression really is!) The proposed Country element DEFinition becomes:
||D "^(?!\\.$|...:|.*@)(.*)" Country C 0 1 ACC 1 R W "Country name" ASMATCHED
Where the regex reads as ^start-of-string followed by (?! is-not ( exp1 |or exp2 |or exp3 ) followed by the ( )capture of ( .any-char * repeated ); exp1 is \\.true-dot immediately followed by $end-of-string; exp2 is .any-char .any-char .any-char :colon ; exp3 is .any-char *repeated followed by @at-sign (matching enough of an email address for excluding it).
An alternative solution is adopting a strategy like the previous not-a-tab-repeated matching of address lines. Indeed, we can assume that a valid country name would not contain : , @ , neither . characters in its name, which any of the possibly following lines do feature.
A sequence of input message structures possibly repeating, possibly optional is simply matched by a corresponding set of DEFinitions, possibly repeating, possibly optional, in just the same sequence and cardinalities. From this basic scheme, we have shown in previous sections that we can flatten the hierarchy of elements, as well as create arbitrary groupings not explicitly present in the input data. This flexibility in creating groupings and erasing element hierarchies is the key to handling un-ordered element sequences as in ACCABCBAC.
We create an NOTAG-group with a DEFinition for each possible un-ordered element as optional group member, alike in this informal notation (not a regex) (A?B?C?), and then we let this NOTAG-group repeat until it has matched all un-ordered input element instances, yielding here (<A><C>)(<C>)(<A><B><C>)(<B>)(<A><C>). The artificial hierarchy and groupings introduced by the NOTAG-group will not appear—by definition—in the final output: <A><C><C><A><B><C><B><A><C> decomposed as expected.
Practically, the telephone, fax, mobile and email lines from our address records are digested by the following set of DEFinitions:
||GRP "^...:|^.*@" Contact O 0 1 ACC 1 R W "Contact group"
|||GRP "^...:|^.*@" NOTAG M 1 5 ACC 5 R W "UNordered matching..."
||||D "Tel:(.*)" Telephone O 0 1 ACC 1 R W "Phone Nb" ASMATCHED
||||D "Fax:(.*)" Fax O 0 1 ACC 1 R W "Fax Nb" ASMATCHED
||||D "Mob:(.*)" MobilePhone O 0 1 ACC 1 R W "Mobile Nb" ASMATCHED
||||D "(.*@.*)" InternetMail O 0 1 ACC 1 R W "eMail..." ASMATCHED
The regex match for a group (GRP) or segment (SEG) deals only with pure identification purposes and then implicitly behaves like a pattern-find operation; whereas the regex match for a data element (D) is about identification and validation, and therefore behaves like a pattern-full-match operation. A regex like "^...:" identifies every chunk of string with a colon as fourth character. A regex like "Tel:(.*)" identifies and validates a complete tagged-value, but captures (with the ( ) next to the tag) only the value portion. A regex like "(.*@.*)" identifies, validates, and captures the entire input string.
The Un-ordered element definitions in proper have been wrapped altogether in an extra Contact group. The NOTAG group at depth 3 cares for the un-ordered element loop, and will disappear in the output XML given it reserved name "NOTAG". On the other hand, the Contact group does not repeat and 'groups' all repeated un-ordered element definitions in a single 'semantic' group.
Advanced concepts: Conditions and Marks
By the end of the DEF file we drive the Parser to perform something really cool: recovering a Country name from the look of the Post Code, whenever the country line is missing in the input file.
This exercise is more academic than really useful in the present transformation case. The purpose is here illustrating the use of CONDitions and MARKs.
A CONDition allows accumulating bits of input strings and/or fixed tokens with each positive identification of a Group (GRP), segment (SEG / MSG), or Data element (D). When the input data has been entirely parsed, all conditions are verified. The verification consists is checking that the regex associated to each condition is matched by the condition values accumulated at a specified depth.
Assume that two data elements DataA and DataB defined at a depth of 4 (with a |||| prefix) exclude each other; more precisely, DataA and DataB can repeat but cannot be mixed. They belong to a repeated segment segAB at depth 3 (hence with a ||| prefix). We can associate the same named condition to both elements and feed this condition with the constant "A" when identifying an instance of DataA, and "B" when identifying an instance of DataB. A DEPTH 3 condition associated to the verification (validation role) pattern A+|B+ (meaning Achar +repeated-once-or-more, |OR, Bchar +repeated-once-or-more ) will do the job of checking the exclusion repeated-DataA-only OR repeated-DataB-only. Indeed, DEPTH 3 matches the segAB level and thus, by construction, concatenates all condition-feeds from the contained DataA and DataB elements. If this condition is miss-declared at DEPTH 2, it would test all together the chain of A's and B's from all repeated segAB instances which is not what we want here. In other words, the condition's DEPTH defines the scope that is relevant to this condition verification; DEPTH 0 being the entire input message.
Conditions are declared with a COND keyword, before the MSG keyword. A validation pattern is associated to each condition. Condition values are fed in the course of parsing with either constant strings or extracted input. Then all conditions are verified only after the entire input file has been parsed. However, there is a possibility to test a CONDition in the course of parsing and insert some fixed value-if-true, or value-if-false according to the outcome of such test. This is achieved with MARKs. Note that a MARK applies its own local condition verification pattern, and matches it against whatever the condition value has accumulated up to the point the MARK is invoked. Let us illustrate.
Our purpose is rebuilding the Country code when missing, based on the 'look' of the PostCode. So we need two pieces of information to proceed:
- The value of the PostCode so as to check its pattern/look;
- Whether or not the country value was present in the input address record.
To do so, a CONDition named POCountry is DEFined above the message (MSG) segment as follows (nearby line 48 in the complete DEF file):
COND POCountry "[A-Z0-9 ]{2,}|.*=C=" DEPTH 1 R W "..error descr.."
Where:
- COND is the keyword
- POCountry is a unique name for this one condition
- The verification pattern is "[A-Z0-9 ]{2,}|.*=C=", meaning: uppercase alphanumericals with space char included of at least 2 chars in size, |OR, .any-char *repeated (possibly zero length) followed by =C= which is, as we will see, the token that we feed into the condition value when a Country is matched in input.
- DEPTH 1 is the actual depth of the entire address Record group (cfr |GRP ... ), which is the right scope of verification for this condition.
- R W instructs to Record a Warning exception in case of verification failure.
The DEFinition line for the PostCode data element (nearby line 67) is amended to contain the condition feed: COND POCountry "(.*)" which actually ( )captures .any-char *repeated, hence the entire data element value is fed into the condition value at this point in the parsing.
The DEFinition line for the Country data element (nearby line 79) is amended to contain the condition feed: COND POCountry "=C=" where the condition feed is "=C=", a fixed string without capturing groups; by convention, constants are fed as such into the condition value, at this point in the parsing.
The Country DEFinition becomes:
||D "^(?!\\.$|...:|.*@)(.*)" Country C 0 1 ACC 1 COND POCountry "=C=" "Country name" ASMATCHED
This DEFinition features now a cardinality C 0 1 ACC 1, meaning Conditional min 0 max 1 and ACCepting 1. Conditional is similar to Optional, but features a named condition that is fed with the associated pattern if the data is positively identified.
A set of MARK definitions follow immediately the Country element definition.
||MARK Country COND POCountry "^[A-Z][A-Z] [0-9]{5}$" "United States" "NULL"
||MARK Country COND POCountry "^F-?[0-9]{5}$" "France" "NULL"
||MARK Country COND POCountry "^D-?[0-9]{5}$" "Germany" "NULL"
||MARK Country COND POCountry "^B-?[0-9]{4}$" "Belgium" "NULL"
||MARK Country COND POCountry "^[A-Z][A-Z0-9]{1,3} [0-9][A-Z]{2}$" "United Kingdom" "NULL"
All these definitions:
- generate the same element tag Country;
- make reference to the same condition value, POCountry, resulting from the latest feeds by an optional PostCode element and an optional Country element;
- feature a distinguished MARK validation pattern, actually exclusive with each other, that will test the value of the designated condition;
- none of these patterns could match a condition value terminating by "=C=". If the Country element was matched by its conditional data definition (the "D" DEFinition), the condition value is postfixed with "=C=" and all MARKs will generate their value-if-false, namely "NULL", meaning that nothing is actually generated at all.
- On the other hand, if "=C=" is missing from the condition value (||D ... Country ... was not matched), one of the MARKs can possibly match the condition value containing at most a copy of the PostCode element value. In which case the corresponding value-if-true like "United States", "France", "Germany", etc. is used to generate a Country element in XML.
Although this example is academic, MARKs are quite useful in practice to make explicit in XML something implicit in the input message.
Because CONDition values can be fed both by constants and by pieces from the input data, they can be used to:
- verify that the presence (or absence) of some element is dependent from the presence of other elements;
- verify that the value of some element triggers the presence (or absence) of other elements;
- verify that the value of some element qualify the value(s) of other element(s);
- verify that the value of some element belongs to a specific range of codes, possibly linked to other element values or presences.
One could still make numerous improvements within the reverseXSL Parsing step itself:
- If the element name/XMLtag of a data element (D line) starts with the character @, it becomes automatically an attribute of the immediate parent element in the XML output;
- Generate a sample output document (invoke the command-line Parser with only the DEFinition file, cfr documentation);
- Generate the schema of the XML output document (cfr. forthcoming release);
- Adjust the thresholds that control the Parser tolerance to syntax errors, so that a malformed address record will not prevent to handle the remaining of the input file.
Taking advantage from the optional XSL transformation step that may be automatically invoked next to Parsing, one can also think of using XSLT for:
- re-ordering or simply sorting the un-ordered Tel:, Fax:, Mob:, e@mail elements in each address Record;
- rebuilding in XSL—and pushing further—the logic that recovers missing Country codes from the look of PostCodes;
- Processing in XSL the phone number formats such as to normalize them;
- Mapping the XML generated by the Parsing step towards a variant schema, or even towards a flat file in another format;
- calculating field values (e.g. total number or Records in the file), and then output or trace them.