Whether IATA Cargo-IMP, AHM, SSIM, SWIFT, EDIFACT, X12, EDIFICE, EANCOM, TRADACOMS, GENCOD, IEF, SPEC-2000... just name them and you can transform these Electronic Data Interchange standards with this tool... both ways: EDI to XML (with the Parser and optionally XSLT) and XML to EDI (with XSLT).
I work since 1988 in the field of electronic trading, have used all the cited formats, and developed message mappings with numerous vendor products. I was often disappointed by at least one of the following three issues:
- Lack of configurability when the remote party sends a message that is acceptable but not strictly conforming to the standard; e.g. extra control-chars, spurious line or record breaks, lowercase, unofficial character sets or encodings, compulsory element missing but actually useless, etc. One may also be confronted to seldom supported formats like a IATA Type-B message containing an EDIFACT envelope wrapping an IMP message;
- Very limited capability in handling proprietary flat-file formats as soon as leaving the grounds of pure "delimited-only" or "fixed-record-only" layouts;
- A overload of clicks, pop-up boxes, click, click, lists, scroll, click, scroll, click, parameters, click, click, click, tab options, click-off click-off click-on click-off click-on, and other indirections, ok-click, ok-click, ok-click... to get simple things done!
While possibly servicing only one (XML to EDI) of the two directions of traffic, XSLT has consequently seldom been used at all. If we open the possibility for XSLT to parse flat files and legacy EDI formats, then we get a powerful, integrated, data mapping tool that works in both ways and that won't fail by any of the above issues.
Table of Contents
- A Product Unlike Others
- The Tutorial Example
- Drafting the DEF File
- Controlling the XML Output: Filter, Flatten, use Attributes
- Controlling the XML Output: Repeating, Regrouping
- Advanced Features
A Product Unlike Others: compact, simple to learn, very simple to deploy, and extremely flexible
Of course the advent of XML has considerably modified the electronic trading landscape, but there are numerous places where legacy EDI standards remain in widespread use, and still do a very good job. At least, the multiplication of XML development tools changed the problem of going from EDI to internal format and internal format to EDI, into going from EDI to XML and XML to EDI. To that respect, XSLT works well in the XML to anything direction, but cannot, by design, service the anything to XML case.
That is exactly where the ReverseXSL software picks-up: digesting meta-data definitions of arbitrary formats, and turning the corresponding message instances to XML. The meta language used in reverseXSL DEF files can describe all kinds of formats, in ASCII, ISO, JIS, or Unicode brands, with plenty of non-printable characters, highly structured like EDI brands, or much unstructured like printed data, and all intermediate character-based formats mixing fixed, variable, and vicious(!) syntax exported from IT applications.
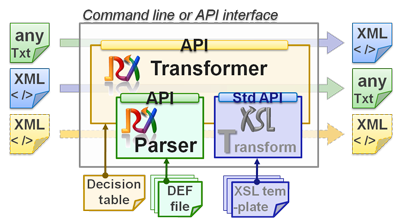
ReverseXSL software is NOT a workstation package with graphical editors for numerous embedded tools and (often limitative) families of formats. ReverseXSL software is neither a library of parsing functions that you'll need to call in a proper sequence in order to advance in the source file and capture data (e.g. like the SAX API). Instead, reverseXSL software is contained in a single java archive, which you invoke from the command line, an Excel macro, or MS-Windows script, or a shell script, or else the java API directly. The reverseXSL software takes your raw EDI or text file as input, uses a message DEFinition file describing the transformation, and produces an XML output.
The reverseXSL software plus a DEF file describing the input syntax is all what is needed!
You can actually put the DEF file in the software archive itself, so you would just need to pass your input data file as argument to a java program contained in a single jar (inclusive of meta-data). Moreover, The ReverseXSL Transformer automates the combined use of XSLT and the reverseXSL Parser, with the help of a mapping decision table. The Transformer identifies arbitrary input messages, looks up the decision table for relevant Transformation steps, and executes these. Therefore, the Transformer maps XML to XML, XML to flat / text or EDI, EDI to XML, text to XML, text to flat, EDI to flat, and so forth. It can also act as a pass-through for selected messages, thus generalizing the means to import and export data for target applications.
The magic is the ease of learning the Message DEFinition files meta language; it contains only five constructs: segments, groups, data elements, marks and conditions. These five constructs organise the use of regular expressions and simple built-in functions to drive parsing and to produce the target XML document.
 The software distribution jar (reverseXSL.jar) contains various samples, but the one at stake here is available separately for download (as zip archive)
The software distribution jar (reverseXSL.jar) contains various samples, but the one at stake here is available separately for download (as zip archive)
The present tutorial describes the mapping of an EANCOM purchase order, itself based on the international EDIFACT standard, although we could have used the American standard X12, the UK standard TRADACOMS, and numerous others. (The software distribution archive contains SWIFT and IATA examples).
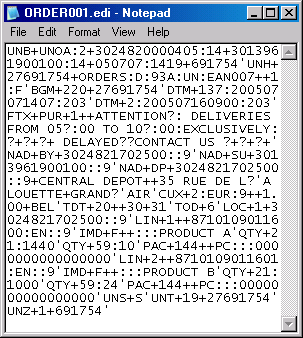
The EDIFACT interchange is illustrated in the enclosed figure. Obviously, this is not much readable; so we have wrapped the interchange on segment boundaries, colored the tags, and indented the structure, as displayed in the second figure.
|
|
The EDIFACT syntax is actually very similar to that of X12 or TRADACOMS. |

The EDIFACT standard allows changing dynamically the specification of separator and terminator characters (with the help of the UNA service segment), I have seldom encountered other brands than the default one based on ', + and : as illustrated. Should you have to handle syntaxical variations, the ReverseXSL software embeds automatic syntax normalization filters that ensure a constant syntax upon entry to the parsing step.
Our objective is to properly segregate the different pieces of information in the EDIFACT EANCOM purchase order, and produce the XML document illustrated further below.
Whereas numerous data mapping software would transform the EDIFACT segment LIN+18+1+54123400009:AM:57:9+2+I' into something like (where the official element IDs become tags):
<LIN>
<1082>18</1082>
<1229>1</1229>
<C212>
<7140>54123400009</7140>
<7143>AM</7143>
<1131>57</1131>
<3055>9</3055>
</C212>
<1222>2</1222>
<7083>I</7083>
</LIN>
the ReverseXSL software, with the help of your DEF file, will produce:
<LineItem Nb="18" Action="1">
<Article>
<Number>54123400009</Number>
<NumberType Qualifier="57" Agency="9">AM</NumberType>
</Article>
<SubLineId>2</SubLineId>
<ConfigLevel>I</ConfigLevel>
</LineItem>
... a much better result!
The complete tutorial sample yields the following XML document:
<?xml version="1.0" encoding="UTF-8"?> |
We also illustrate the case of data fields containing the delimiter characters as literals in their value, hence escaped in EDIFACT with the so-called release character, here the ?. As you may observe, the corresponding character values are properly un-escaped in the XML output (cfr explanation at the end of this tutorial). |
You can run the tutorial example by executing the DOS batch file supplied in downloadable material. This is simplistic but easier during training, development, and testing. The best method is indeed to integrate the reverseXSL software inside your run-time application by calling the java API as explained in the javadoc.
The DEF file entirely defines the parsing of the EDIFACT input and its transformation to XML. The DEF file contains nested segments (SEG), groups (GRP) and data (D) definitions.
EDIFACT Segments and DEF Segments share a same name, but are completely different things. Within EDIFACT, a segment is a basic building block that aggregates a few simple or composite data elements around a concept like a date, a party, an article description, a tax, a quantity, and so forth. EDIFACT segments are distinguished by their tags. Within a DEF file, a segment is used to 'segment' a string into sub-strings such as to parse the next sub-level. Therefore, DEF segments are used to cut-down the entire message into EDIFACT segments, then the individual EDIFACT segments into simple or composite data elements, then the composite data elements into their component elements, and structured elements further down into their constituent pieces (e.g. a YYMMDD date element value into YY, MM, and DD constituents).
You may like to open a separate window on the entire DEF file. Next to a full page of comments, a DEF file is always comparable in size to an XML schema for the target document.
The first important piece of meta data in the DEF file is the MSG definition (nearby line 56), which is actually a SEGment matching the entire file:
MSG "^UN[AB]" EAN-Orders-v7 M 1 1 ACC 1 T F "EDIFACT Interchange containing EANCOM ORDERS V007" CUT-ON-(')
- MSG is the keyword. MSG is the topmost DEF SEGment.
- "^UN[AB]" is actually a regex (regular expression) used to identify this DEF structure: the regex matches ^start-of-input followed by UNA or UNB. The Parser therefore checks that the entire file/message starts with "UNA..." or "UNB..." as one shall expect for a valid EDIFACT interchange.
- EAN-Orders-v7 defines the XML root element name.
- M 1 1 ACC 1 is fixed in case of a MSG. It tells that this structure is Mandatory, formally occurs min=1 and max=1, and the Parser can actually ACCept 1.
- T F instructs to Trhrow a Fatal exception if anything goes wrong with the present parsing activity (identifying and cutting the overall message).
- then follows a "description..." to be reported in error messages.
- then follows the CUTting function, here CUT-ON-('), a built-in function telling to simply CUT the current input string (the entire-file at this stage) ON single ' chars, serving as actual EDIFACT segment terminators.
The outcome of all this is that the Parser assumes the entire file as being an EDIFACT interchange and cuts it down in individual EDIFACT segments. A Fatal exception will be Thrown on the unlikely event that the cut fails.
We will see further how this simple CUT function distinguishes correctly the ' chars used in data values versus the ' chars actually standing as EDIFACT segment terminators, without being specific to EDIFACT.
The result from the MSG cut is a collection of string pieces which are in turn each presented for potential matches to the sequence of DEFinition objects in the DEF file.
The very next object is either the EDIFACT UNA service segment, else directly the UNB interchange header. We don't have any interest at this point in segmenting the UNA structure further down, so we use directly a data DEFinition to possibly match this EDIFACT segment. On the other hand, the UNB structure obviously requires further segmenting to get access to data element values; a DEF SEGment is therefore used to match it and segment it further down. We get the following draft DEFinition:
MSG "^UN[AB]" EAN-Orders-v7 M 1 1 ACC 1 T F "EDIFACT Interchange containing EANCOM ORDERS V007" CUT-ON-(')
|D "^UNA(.*)" SKIP O 0 1 ACC 1 R W "UNA service segment - skipped" ASMATCHED
|SEG "^UNB" InterchangeHeader M 1 1 ACC 1 T F "UNB Interchange Header" CUT-ON-(+)
... more Data/SEG/Group DEFinitions to provide here ...
END
- The MSG, SEG and D lines are very similar; The last element of MSG and SEG definition lines is a CUT function. In case of a D data definition line, it is a data value validation function. In particular, ASMATCHED means than no further validation is performed beyond matching the regular expression "^UNA(.*)" at the beginning of Data DEF line. Such reg'exp plays a twofold role in D DEF lines: a) as a means to identify an occurence of the Data. b) as a value extraction tool, based on the capturing group(s) in the regular expression. Here (.*) tells to ()capture ( .any char *repeated ), next to the U N A letters.
- Both the D and SEG lines are prefixed by a single | indicating a hierarchical depth of 1, hence as children of the entire MSG DEFinition.
- The regex "^UNB" in the SEG line matches an input string piece (resulting from the MSG cut) ^starting with U N B , hence the EDIFACT Interchange header segment.
- SKIP and InterchangeHeader are the XML output tags associated to the matched data structures, respectively the EDIFACT UNA segment matched as a DEF Data element, and the EDIFACT UNB segment matched as a DEF SEGment. SKIP is a reserved tag name that will cause the corresponding element to be skipped in the XML output, whereas InterchangeHeader is a regular name which you can identify in the sample XML output already presented.
- The cardinality O 0 1 ACC 1 of the UNA Data DEFinition indicates an Optional element, formally entitled to occur min=0 and max=1, and for which the Parser ACCepts up to 1. The cardinality M 1 1 ACC 1 of the UNB SEGment DEFinition indicates a Mandatory element entitled to occur min= 1 and max= 1 , and for which the Parser ACCepts 1 .
- The R W and T F flags respectively request to Record a Warning, else Throw a Fatal exception in case anything goes wrong with the parsing of the relevant definitions.
- The UNB SEG definition is terminated with the built-in CUT function CUT-ON-(+) asking to segment further down this structure on + chars as delimiters.
The outcome of the CUT-ON-(+) is the segmentation of the entire UNB segment:
UNB+UNOA:2+3024820000405:14+3013961900100:14+050707:1419+691754
into the following pieces:
UNB
UNOA:2
3024820000405:14
3013961900100:14
050707:1419
691754
The above DEFinition is still much incomplete: we do not tell what we do with all the pieces resulting from the UNB segment cut (the CUT-ON-(+) ), and there are also numerous EDIFACT segments following the UNB (UNH.. BGM.. DTM.. DTM.. etc. resulting from the MSG-level CUT-ON-(') ) for which we also have to tell what to do.
Let's adopt a fairly brute Parsing approach at this point in the tutorial (and improve it later on).
- As far as the pieces from the UNB segment cut are concerned, let's match them as un-parsed data element values.
Then: - Every EDIFACT segment that follows is matched as a generic segment and cut further down onto + delimiter chars.
- The EDIFACT segment tag which is the first piece from this cut is promoted as an XML attribute.
- The subsequent pieces are cut further down onto : delimiter chars. For a simple EDIFACT data elements that contains no ":" sub-delimiters, the result is the element itself. For composite EDIFACT data elements, the result is the list of component elements.
- Then the resulting (sub)pieces are matched as data element values.
The DEFinition that fulfills all the above becomes:
MSG "^UN[AB]" EAN-Orders-v7 M 1 1 ACC 1 T F "EDIFACT Interchange containing EANCOM ORDERS V007" CUT-ON-(')
|D "^UNA(.*)" SKIP O 0 1 ACC 1 R W "UNA service segment - skipped" ASMATCHED
|SEG "^UNB" InterchangeHeader M 1 1 ACC 1 T F "UNB Interchange Header" CUT-ON-(+)
||D "(.*)" UnParsedStuff M 1 99 ACC 99 R W "Segment Tag" ASMATCHED
|SEG "" _Seg O 0 999 ACC 999 R W "Generic EDIFACT Segment" CUT-ON-(+)
||D "(.*)" @Tag M 1 1 ACC 1 R W "Segment Tag" ASMATCHED
||SEG "" _Data O 0 999 ACC 999 R W "Generic simple or composite Data" CUT-ON-(:)
|||D "(.*)" _Val O 0 999 ACC 999 R W "Generic (Sub)Element Value" ASMATCHED
END
- The UnparsedStuff data element definition starts with || making it a depth 2 definition, hence a child of the preceding depth 1 definition, namely the UNB InterchangeHeader segment. Similarly, the following _Seg segment definition features only one |, thus at depth 1 like the UNB segment which it follows, and a child of the depth 0 MSG element.
- The _Seg definition is repeated (cardinality is Optional min=0 max=999 ACCepting 999); it will match in sequence every input string piece resulting from the parent MSG cut (thanks to the "" empty identification pattern), and cut further down these input pieces on + chars (thanks to CUT-ON-(+) ).
- The _Seg definition features two depth-level-2 children (bearing leading || ): a @Tag Data element definition, and a sub-segment named _Data, itself executing a sub-cut on :. The string pieces resulting from this sub-cut are matched against repeated _Val Data element definitions, logically at depth level 3.
- All Data pieces are validated with the generic pattern "(.*)" (meaning .any-char *repeated). The entire data piece is captured as data value by the enclosing ()capturing group. Moreover, the captured values are not validated further as specified by the ASMATCHED data-value-validation functions used elsewhere. If one had for instance specified UPALPHA as data-value-validation function, the captured data values would have been checked against the uppercase alphabetical character subset.
- When a @ char prefixes a Data Element name, the corresponding element is by convention grafted into the XML output tree as an attribute node instead of a child-element node.
The above 9 DEFinition lines form a complete self-standing definition for any EDIFACT Interchange. We can readily ask the Parser to apply this definition to our EDIFACT message sample. And this yields:
<?xml version="1.0" encoding="UTF-8"?>
<EAN-Orders-v7 xmlns="http://www.HelloWorld.com" messageID="1">
<InterchangeHeader>
<UnParsedStuff>UNB</UnParsedStuff>
<UnParsedStuff>UNOA:2</UnParsedStuff>
<UnParsedStuff>3024820000405:14</UnParsedStuff>
<UnParsedStuff>3013961900100:14</UnParsedStuff>
<UnParsedStuff>050707:1419</UnParsedStuff>
<UnParsedStuff>691754</UnParsedStuff>
</InterchangeHeader>
<_Seg Tag="UNH">
<_Data>
<_Val>27691754</_Val>
</_Data>
<_Data>
<_Val>ORDERS</_Val>
<_Val>D</_Val>
<_Val>93A</_Val>
<_Val>UN</_Val>
<_Val>EAN007</_Val>
</_Data>
<_Data>
<_Val></_Val>
</_Data>
<_Data>
<_Val>1</_Val>
<_Val>F</_Val>
</_Data>
</_Seg>
<_Seg Tag="BGM">
<_Data>
<_Val>220</_Val>
</_Data>
<_Data>
<_Val>27691754</_Val>
</_Data>
</_Seg>
<_Seg Tag="DTM">
<_Data>
<_Val>137</_Val>
<_Val>200507071407</_Val>
<_Val>203</_Val>
</_Data>
</_Seg>
... and much more taking place here ...
<_Seg Tag="UNS">
<_Data>
<_Val>S</_Val>
</_Data>
</_Seg>
<_Seg Tag="UNT">
<_Data>
<_Val>19</_Val>
</_Data>
<_Data>
<_Val>27691754</_Val>
</_Data>
</_Seg>
<_Seg Tag="UNZ">
<_Data>
<_Val>1</_Val>
</_Data>
<_Data>
<_Val>691754</_Val>
</_Data>
</_Seg>
</EAN-Orders-v7>
Beside the UNB segment DEFinition that we would still want to improve, the outcome is a decomposition of the entire EDIFACT interchange that is already suitable for an XSL Transformation. Many data mapping engines would actually not give a much richer intermediate 'EDIFACT-in-XML' format. But you can go much further with ReverseXSL software, as will be illustrated through the rest of this tutorial.
Controlling the XML Output Tree Contents and Structure: Filter, Flatten, use Attributes
We illustrate here how we can enhance in XML the visibility of semantical dependencies only indirectly documented in raw EDIFACT segment structures. We take the EDIFACT FTX (Free TeXt) segment as example. The original EDIFACT segment definition runs as follows:
FTX FREE TEXT
Function: To provide free form or coded
text information.
010 4451 TEXT SUBJECT QUALIFIER M an..3
020 4453 TEXT FUNCTION, CODED C an..3
030 C107 TEXT REFERENCE C
4441 Free text, coded M an..3
1131 Code list qualifier C an..3
3055 Code list responsible agency C an..3
040 C108 TEXT LITERAL C
4440 Free text M an..70
4440 Free text C an..70
4440 Free text C an..70
4440 Free text C an..70
4440 Free text C an..70
050 3453 LANGUAGE, CODED C an..3
We can match exactly this structure with the following DEFinition block:
||SEG "^FTX" FTXseg O 0 5 ACC 5 R W "FTX Free Text" CUT-ON-(+)
|||D "(.*)" Tag M 1 1 ACC 1 T F "FTX segment tag" ASMATCHED
|||D "(.*)" SubjectQual M 1 1 ACC 1 R W "FTX-4451 TEXT SUBJECT QUALIFIER" ASMATCHED [1..3]
|||D "(.*)" Function O 0 1 ACC 1 R W "FTX-4453 TEXT FUNCTION, CODED" ASMATCHED [1..3]
|||SEG "" Reference O 0 1 ACC 1 R W "FTX-C107 composite data" CUT-ON-(:)
||||D "(.*)" FreeCode M 1 1 ACC 1 R W "FTX-4441 - Free text, coded" ASMATCHED [1..3]
||||D "(.*)" Qualifier O 0 1 ACC 1 R W "FTX-1131 - Code list qualifier" ASMATCHED [1..3]
||||D "(.*)" Agency O 0 1 ACC 1 R W "FTX-3055 - Code list responsible agency, coded" ASMATCHED [1..3]
|||SEG "" Text O 0 1 ACC 1 R W "FTX-C108 composite data" CUT-ON-(:)
||||D "(.*)" Literal M 1 5 ACC 5 R W "FTX-4440 - Free text" ASMATCHED [1..70]
There is already a simplification in the above with regard to the original EDIFACT definition. In fact, as indicated by the cardinality M 1 5 ACC 5, the Data element 4440 'Free Text' repeats 1 to 5 times within the composite C108 'TEXT LITERAL', itself being Optional.
We shall note that:
- Simple EDIFACT Data Elements are directly matched onto a corresponding Data DEFinition
- Composite EDIFACT ELEMENTS (like C107 & C108) are matched against a sub-SEGment DEFinition, cutting the piece further down on the : character, then matching each sub-piece with a corresponding Data DEFinition
- Data DEFinition lines are all terminated by a range specification like [1..70] that validates the min and max size of the corresponding data value counted in characters (not bytes).
Applying the above DEFinition block to an EDIFACT FTX segment like
FTX+AAH+4+123:ZZZ:9+TEXT ONE:TEXT TWO:TEXT THREE
Yields the XML fragment:
<FTXseg>
<Tag>FTX</Tag>
<SubjectQual>AAH</SubjectQual>
<Function>4</Function>
<Reference>
<FreeCode>123</FreeCode>
<Qualifier>ZZZ</Qualifier>
<Agency>9</Agency>
</Reference>
<Text>
<Literal>TEXT ONE</Literal>
<Literal>TEXT TWO</Literal>
<Literal>TEXT THREE</Literal>
</Text>
</FTXseg>
Not too bad, but we can do much better with the following variant DEFinition block (changes are highlighted):
||SEG "^FTX" Info O 0 5 ACC 5 R W "FTX Free Text" CUT-ON-(+)
|||D "(FTX)" SKIP M 1 1 ACC 1 T F "FTX segment tag" ASMATCHED
|||D "(.*)" @Subject M 1 1 ACC 1 R W "FTX-4451 TEXT SUBJECT QUALIFIER" ASMATCHED [1..3]
|||D "(.*)" @Function O 0 1 ACC 1 R W "FTX-4453 TEXT FUNCTION, CODED" ASMATCHED [1..3]
|||SEG "" Coded O 0 1 ACC 1 R W "FTX-C107 composite data" CUT-ON-(:)
||||D "(.*)" NOTAG M 1 1 ACC 1 R W "FTX-4441 - Free text, coded" ASMATCHED [1..3]
||||D "(.*)" @Qualifier O 0 1 ACC 1 R W "FTX-1131 - Code list qualifier" ASMATCHED [1..3]
||||D "(.*)" @Agency O 0 1 ACC 1 R W "FTX-3055 - Code list responsible agency, coded" ASMATCHED [1..3]
|||SEG "" NOTAG O 0 1 ACC 1 R W "FTX-C108 composite data" CUT-ON-(:)
||||D "(.*)" Literal M 1 5 ACC 5 R W "FTX-4440 - Free text" ASMATCHED [1..70]
- We have first renamed the whole structure Info in place of FTXseg such as to reflect the semantics of being additional information inside the message. The choice of good tag names is actually very helpful.
- Second, the XML tag name Info is explicit enough about the semantics, and the first output child element <Tag>FTX</Tag> becomes consequently useless. The reserved name SKIP will cause this element to disappear from the XML output.
- The next two elements are output as attribute nodes (thanks to the @ in front of the name) of the parent element, here Info. It reflects better the semantics of these elements in EDIFACT, as qualifiers of the whole block of free text Information.
- The next EDIFACT piece is a composite (C107) containing a possibly coded form of the whole Information. It contains three pieces: a) the code value itself, b) another code telling to which family of codes the actual code value belongs, c) the code of the agency maintaining this family of codes—sorry for this complexity, but this is EDIFACT! Definitely, those three pieces would look better in XML as a main Coded element with 2 attributes: Qualifier and Agency. The changes made rename the whole composite as Coded, attach the actual code value directly as child text node to the parent Coded element (thanks to the reserved name NOTAG that suppresses this intermediate element level in the output XML), and attach the next two elements as attributes (thanks to the leading @ in the name).
- The next, and last, EDIFACT piece is a second composite (C108) that contains true free text literals. We shall match it with a segment DEFinition in order to cut it further down on : delimiter characters. Sub-pieces are matched as repeating Literal element instances. The parent level of the composite itself (the SEG definition) is useless as intermediate element structure; it is suppressed from the XML output with the help of the NOTAG reserved name.
The modified DEFinition block applied to the same input EDIFACT segment now yields:
<Info Function="4" Subject="AAH">
<Coded Agency="9" Qualifier="ZZZ">123</Coded>
<Literal>TEXT ONE</Literal>
<Literal>TEXT TWO</Literal>
<Literal>TEXT THREE</Literal>
</Info>
Not only this is much more compact, but also much more readable.
Controlling the XML Output Tree Contents and Structure: Repeating, Regrouping
EDIFACT mixes hierarchical (nested groups and segment) with positional syntax (data elements within segments). XML is clearly hierarchical in nature. Therefore, on several occasions we find a sequence of EDIFACT elements in which subsets bear implicit semantic links. Let us illustrate this case with the EDIFACT PIA (Additional Product Identification) segment whose original definition is:
PIA ADDITIONAL PRODUCT ID
Function: To specify additional or substitutional
item identification codes.
010 4347 PRODUCT ID. FUNCTION QUALIFIER M an..3
020 C212 ITEM NUMBER IDENTIFICATION M
7140 Item number C an..35
7143 Item number type, coded C an..3
1131 Code list qualifier C an..3
3055 Code list responsible agency, coded C an..3
030 C212 ITEM NUMBER IDENTIFICATION C
7140 Item number C an..35
7143 Item number type, coded C an..3
1131 Code list qualifier C an..3
3055 Code list responsible agency, coded C an..3
040 C212 ITEM NUMBER IDENTIFICATION C
7140 Item number C an..35
7143 Item number type, coded C an..3
1131 Code list qualifier C an..3
3055 Code list responsible agency, coded C an..3
050 C212 ITEM NUMBER IDENTIFICATION C
7140 Item number C an..35
7143 Item number type, coded C an..3
1131 Code list qualifier C an..3
3055 Code list responsible agency, coded C an..3
060 C212 ITEM NUMBER IDENTIFICATION C
7140 Item number C an..35
7143 Item number type, coded C an..3
1131 Code list qualifier C an..3
3055 Code list responsible agency, coded C an..3
The content of this PIA segment structure is obviously very repetitive. The composite data element C212 is repeated up to 5 times; the first one is Mandatory. The ReverseXSL Parser needs a single SEGment definition matching the composite, which will be allowed to repeat from 1 to 5 times with the cardinality M 1 5 ACC 5, meaning: Mandatory, with a formal minimum of 1 and maximum of 5, and actually ACCepting 5 in this one message.
The cardinality notation allows differentiating formally specified limits from those practically accepted for parsing purposes. For instance, a setting like O 1 2 ACC 5 indicates that the element is Optional (parsing will not fail if not found) and the parser can ACCept 5 repetitions (parsing may tolerate such repetitions). However, any deviation from min 1 and max 2 occurrences will be reported in an exception that can be Thrown or Recorded, of level Warning or Fatal, as specified by the next two letters in each DEF line.
Having digested the repetition, we shall focus on the sub-structure of the composite element itself (C212). The 4 pieces that appear in sequence must be read as 1 + 3 ! Indeed, we have an Item Number value (ref 7140), followed by the classical 3 stage qualifier in EDIFACT: a) a code (ref 7143) telling which type of Item Number we have; b) another code (ref 1131) telling to which family of type-codes the actual type-code value belongs; c) the code (ref 3055) of the agency maintaining this family of type-codes. Sorry—again—for this complexity, but this is EDIFACT! Definitely, those three pieces would look better in XML as a main NumberType element with 2 attributes: Qualifier and Agency. This does imply that we have to group the last three elements out of the four and create a hierarchy that does not exist in the original EDIFACT segment. This is very simply achieved with a Group (GRP) DEFinition, as presented below.
Taking advantage of repetitions and groupings, the proposed PIA segment DEFinition block becomes:
|||SEG "^PIA" ProductId O 0 25 ACC 1 R W "PIA Additional Product Information" CUT-ON-(+)
||||D "(PIA)" SKIP M 1 1 ACC 1 T F "PIA segment tag" ASMATCHED
||||D "(.*)" @Function M 1 1 ACC 1 R W "PIA-4347 PRODUCT ID FUNCTION QUALIFIER" ASMATCHED [1..3]
||||SEG "" Article M 1 5 ACC 5 R W "PIA-C212 composite data" CUT-ON-(:)
|||||D "(.*)" Number O 0 1 ACC 1 R W "PIA-7140 - Item number" ASMATCHED [1..35]
|||||GRP "" NumberType O 0 1 ACC 1 R W "PIA-7143 - Item number type, coded"
||||||D "(.*)" NOTAG O 0 1 ACC 1 R W "PIA-7143 - Item number type, coded" ASMATCHED [1..3]
||||||D "(.*)" @Qualifier O 0 1 ACC 1 R W "PIA-1131 - Code list qualifier" ASMATCHED [1..3]
||||||D "(.*)" @Agency O 0 1 ACC 1 R W "PIA-3055 - Code list responsible agency, coded" ASMATCHED [1..3]
- The first data element (ref 4347) of this EDIFACT segment is logically grafted as a Function attribute of the PIA/ProductId element itself.
- The Article SEGment DEFinition may repeatedly parse the input C212 composite element thanks to the cardinality M 1 5 ACC 5 described above.
- The Group DEFinition NumberType creates an artificial hierarchical level (at depth 5 |||||) that will capture the parsing productions of the next three child elements (at depth 6 ||||||). Data element 7143 is directly grafted as a text node into the parent NumberType (the reserved name NOTAG suppresses the intermediate element node level). In other words, we create a hierarchical level and just next we suppress one! This is indeed a trick that allows grafting the following two elements, 1131 and 3055, as attribute nodes into NumberType.
When applied to the input EDIFACT segment:
PIA+1+ABC123:ZZZ:57:90+BOX-G4:ZZZ:67:90
One gets the output XML fragment:
<ProductId Function="1">
<Article>
<Number>ABC123</Number>
<NumberType Agency="90" Qualifier="57">ZZZ</NumberType>
</Article>
<Article>
<Number>BOX-G4</Number>
<NumberType Agency="90" Qualifier="67">ZZZ</NumberType>
</Article>
</ProductId>
We have just illustrated the use of Group DEFinitions for grouping several data elements inside an EDIFACT segment. Actually, Group DEFinitions are essential to the grouping of sequences of EDIFACT segments into repeated collections of segments (and sub-groups), possibly nested in each other, that form the structure of the EDIFACT message itself. (This is documented in the complete DEF file.)
- The EDIFACT UNH...UNT message istelf is defined as a Message group
- ...containing DEFinitions for segments UNH.. BGM.. DTM.. FTX..
- ...followed by a repeatable Party group starting with the NAD.. segment
- ...followed by a repeatable Currencies group ..and more
- ...followed by a repeatable Transport details group ..and more
- ...followed by a repeatable TransportTerms group ..and more
- ...followed by a repeatable LineItem group:
- ......containing DEFinitions for segments LIN.. PIA.. IMD.. MEA.. QTY.. DTM.. MOA.. /li>
- ......followed by a repeatable Packaging group ..
- ...followed by DEFinitions for segments UNS.. MOA.. CNT.. and UNT..
The following two features take advantage from named CONDitions. CONDitions are declared with the COND keyword near the top of the DEF file, just above the very first parsing statement "MSG ...". A CONDition features a unique name, a depth scope (used for grouping tokens at the specified depth and below), and a regular expression pattern. The later is used for verifying the condition itself (via pattern matching TRUE/FALSE) over the set of tokens collected under that unique name while parsing the message itself.
Whenever a named CONDition is associated to a segment (SEG), group (GRP) or data element (D) DEFinition, and an instance of that element is found in the parsed input message, a token (a piece of string) is generated. Therefore, tokens reflect the existence of certain structural elements in the message. The value of each token can be either a constant string, or a value extracted from the parsed element itself.
CONDitions can be used for two purposes:
- Collecting values (or a set of) and/or information about the existence of certain elements at some point in the message, and then reusing this information later on for generating default values or flag-style XML elements with the help of MARKS.
- Collecting values (or a set of) and/or information about the existence of certain elements throughout the message, and then, when the parsing itself is completed, verifying that this information complies with expected patterns. This mechanism allows validating interdependencies between the existence of certain elements and values of other elements, or values depending from other values, or existence of elements constrained by the existence of other elements, and so forth.
Early Code Mapping with Conditions and Marks
It is well known that dates can be communicated in a variety of formats, with or without time information, as in 2009-08-22 17:42, 2009/22/08 5H42 PM +0200, 220809, August 22nd 2009, 200908221742CET, and many more. EDIFACT allows using over 70 possible formats, each one being identified by a distinguished qualifier code. In practice, trading parties use only very few of those formats according to the business context and EDIFACT subset at stake, else a bilateral agreement. For instance, code "101" indicates a "YYMMDD" format; "102" stands for "CCYYMMDD"; "203" specifies "CCYYMMDDHHMM".
With the help of a CONDition and several MARKs, we can map the cryptic codes like 101, 102, 203 into their equivalent readable code strings "YYMMDD", "CCYYMMDD", and "CCYYMMDDHHMM".
- The CONDition captures the code value with the regex "(.*)" highlighted below—telling to ()capture ( .any-char *repeated ). In our case, this will be the first and only token collected by the CONDition.
- By design, a MARK tests a CONDition in the course of parsing and inserts a defined value-if-true, or value-if-false according to the outcome of such test. Note that a MARK applies its own local condition verification pattern, and matches it against the condition string. This string concatenates all tokens collected by the named CONDition up to the point the MARK is invoked.
The EDIFACT DTM segment contains a single composite data element. Its specification appears as follows in EDIFACT directories:
DTM DATE/TIME/PERIOD
Function: To specify date, and/or time, or period.
010 C507 DATE/TIME/PERIOD M
2005 Date/time/period qualifier M an..3
2380 Date/time/period C an..35
2379 Date/time/period format qualifier C an..3
We declare a CONdition as follows:
COND DateTimeFormat "101|102|201|203" DEPTH 3 R W "one of (coded) YYMMDD(101), CCYYMMDD(102), YYMMDDHHMM(201), CCYYMMDDHHMM(203)"
The associated Condition verification pattern "101|102|201|203" ensures that only one of 101 or 102 or 201 or 203 is accepted as code value. If such verification fails, the Parser Records a Warning exception.
The DTM segment DEFinition block is:
||SEG "^DTM" DateTime M 1 35 ACC 2 R W "DTM Date and Time" CUT-ON-(+)
|||D "(DTM)" SKIP M 1 1 ACC 1 T F "DTM segment tag" ASMATCHED
|||SEG "" NOTAG M 1 1 ACC 1 R W "DTM-C507 composite data" CUT-ON-(:)
||||D "(.*)" @Qual M 1 1 ACC 1 R W "DTM-2005 - Date/time/period qualifier" ASMATCHED [1..3]
||||D "(.*)" NOTAG O 0 1 ACC 1 R W "DTM-2380 - Date/time/period" ASMATCHED [1..35]
||||D "(.*)" SKIP C 0 1 ACC 1 COND DateTimeFormat "(.*)" "DTM-2379 - Date/time/period format qualifier" ASMATCHED [1..3]
||||MARK @Fmt COND DateTimeFormat "101" "YYMMDD" "NULL"
||||MARK @Fmt COND DateTimeFormat "102" "CCYYMMDD" "NULL"
||||MARK @Fmt COND DateTimeFormat "201" "YYMMDDHHMM" "NULL"
||||MARK @Fmt COND DateTimeFormat "203" "CCYYMMDDHHMM" "NULL"
- Data element '2380' is named NOTAG, hence the captured input datetime value will be grafted as text node directly inside its parent. The immediate parent is the SEGment DEFinition for the composite 'C507' which is itself named NOTAG, therefore passing the text node to its own parent. Consequently, the datetime value will become a text node of the top DateTime element, two levels above.
- Data element '2379' is associated to the DateTimeFormat condition. The entire element is captured into the condition according to the specified regex "(.*)". But this Data element DEFinition itself will not be inserted into the XML output because of the reserved name SKIP.
- Just next follows a series of four MARKs, each one testing the condition value against one of the possible codes. Each MARK inserts a Fmt attribute node with the readable equivalent code as value-if-true, and nothing else (NULL) when there is a false match.
When applied to the following input DTM EDIFACT segment:
DTM+137:200507071407:203
One gets the output XML fragment:
<DateTime Fmt="CCYYMMDDHHMM" Qual="137">200507071407</DateTime>
Inside which the code value "203" has been mapped onto the explicit "CCYYMMDDHHMM". Of course, we could do so for numerous other codes; there is actually a balance to adopt between code mappings performed within the parsing step, within a post-XSL Transformation step, else within the target application itself. The best choice depends from the operational context, the stability of the code list and the number of codes to map.
CONDitions were initially designed for the verification of inter-dependencies. They apply both to value and to structural dependencies; for instance between the existence of certain elements and the values of other elements, or between some values and other values, or when the existence of some elements is constrained by the existence of other elements, and any other combination.
An EDIFACT interchange bears a unique reference number, appearing in the UNB interchange header segment, that is repeated in the trailing UNZ interchange termination segment for the sake of controlling the integrity of the interchange. We can extract both reference numbers and verify that they match with each other using a CONDition.
The CONDition is declared as follows:
COND MatchingInterchgRefs "(^.*?)~\\1$" DEPTH 0 R F "Interchange references in UNB/UNZ must be identical to ensure Interchange integrity"
The regular expression pattern "(^.*?)~\\1$" is used to validate the condition. One shall read it as follows:
()capture in a first capturing group ( from ^start-of-input-value .any-char *repeated ?reluctantly ) up to the
following ~ char
followed by \\1==the copy of what has been captured by the 1'st capturing group
followed by $end-of-input-value
The condition is declared at depth 0, obviously taking the whole input interchange file in scope.
Then within the UNB Interchange Header segment we find a data element declared as:
||D "(.*)" Reference C 1 1 ACC 1 COND MatchingInterchgRefs "(.*)" "UNB-0020 - INTERCHANGE CONTROL REFERENCE" ASMATCHED [1..14]
- This first reference to the condition feeds the entire input data value, hence the interchange control number, into the named condition MatchingInterchgRefs, thanks to the capture-everything regex (.*).
And by the end of the DEFinition file, the UNZ Interchange Termination segment is declared as:
|SEG "^UNZ" InterchangeTrailer M 1 1 ACC 1 R W "UNZ Service Segment - Interchange Trailer" CUT-ON-(+)
||D "(UNZ)" SKIP C 1 1 ACC 1 COND MatchingInterchgRefs "~" "UNZ segment tag" ASMATCHED
||D "(.*)" MessageCount M 1 1 ACC 1 R W "UNZ-0036 INTERCHANGE CONTROL COUNT" NUMERIC [1..6]
||D "(.*)" Reference C 1 1 ACC 1 COND MatchingInterchgRefs "(.*)" "UNZ-0020 INTERCHANGE CONTROL REFERENCE" ASMATCHED [1..14]
- The existence of the UNZ segment tag is guaranteed and thus feeds the fixed one-char string ~ into the named condition MatchingInterchgRefs.
- Further down, the Reference data element DEFinition feeds its entire input value (thanks to (.*) ) into the same named condition MatchingInterchgRefs
At this point, the named condition contains the control-number-value-found-in-UNB followed by a ~ char, followed by the control-number-value-found-in-UNZ. In the case of our interchange example, this value will be 691754~691754.
The parsing terminates because we reach the END of the entire DEFinition. This is the moment all named conditions are verified, notably the one named MatchingInterchgRefs. The input condition value 691754~691754 positively matches the regex "(^.*?)~\\1$", which satisfies the condition.
The verification is done.
Literal or Delimiter? Handling the Release Character
The EDIFACT standard, like a few others, makes use of commonplace characters (by default the ' + and : ) to delimit data fields. In the case such character is needed as part of a data field value, the standard requires preceding this character with the so-called release character (by default ? ) such as to "escape" from an interpretation as delimiter, and enforce interpretation as literal value.
The sample EDIFACT interchange contains several segments with escaped delimiter-char literals. For instance (true delimiters are underlined):
FTX+PUR+1++ATTENTION?: DELIVERIES FROM 05?:00 TO 10?:00:
EXCLUSIVELY: ?+?+?+ DELAYED??CONTACT US ?+?+?+ '
and also
NAD+DP+302480250::9+CENTRAL DEPOT++35 RUE DE L?'ALOUETTE+GRAND?'AIR'
Clearly, the literals + ' and : would pollute the segmentation process if the Parser is not made aware of the possibility of escape sequences based on a release character. Moreover, we should expect clean data field values, precisely without the extra release characters, in the output XML document whose syntax is exempt from potential conflicts with + ' and : in literal values.
The solution consists in declaring the release character with the following statement at the very beginning of the DEF file:
SET RELEASECHARACTER '?' for a single printable char
or
SET RELEASECHARACTER '\\u0037' for a single Unicode char
Then each time the Parser matches a delimiter during segmentation operations (i.e. executing a segment CUT function), and the delimiter is one character long, the Parser verifies that the just preceding character is not a release character (precisely, an odd count of release characters), otherwise the matched delimiter is a literal character to ignore and this possible CUT point must be skipped. Moreover, release characters are removed from the extracted data values and from collected CONDition tokens, such as to get the plain, original, un-escaped strings in the output XML document and for testing conditions.